

Computer Vision ist ein multidisziplinäres Gebiet, das Maschinen in die Lage versetzt, visuelle Informationen aus der Welt zu interpretieren und zu verstehen und dabei die Wahrnehmungsfähigkeiten des menschlichen Sehens widerzuspiegeln. Diese transformative Technologie findet nicht nur in der Automobilindustrie Anwendung, sondern auch in verschiedenen anderen Bereichen, vom Gesundheitswesen über Sicherheitssysteme bis hin zur Unterhaltung. In diesem Artikel werden wir uns mit den technischen Feinheiten der Computer Vision befassen, ihre grundlegenden Prinzipien erforschen und uns auf ihre Anwendungen mit nachvollziehbaren Lösungen für die Schadenserkennung bei Autos konzentrieren.Im Kern geht es bei der Computer Vision um die Entwicklung von Algorithmen und Modellen, die es Maschinen ermöglichen, Erkenntnisse aus visuellen Daten zu gewinnen. Der Prozess kann in mehrere wichtige Schritte unterteilt werden:
1. Bilderfassung: Erfassen von visuellen Daten durch verschiedene Sensoren wie z.B. Kameras.
2. Vorverarbeitung: Säubern und Verbessern der aufgenommenen Bilder zur besseren Analyse.
3. Merkmalsextraktion: Identifizierung relevanter Muster oder Merkmale in den Bildern.
4. Entscheidungsfindung: Die extrahierten Merkmale sinnvoll nutzen, um Schlussfolgerungen zu ziehen oder Maßnahmen zu ergreifen.
Wie funktioniert Computer Vision?
Computer Vision stützt sich auf umfangreiche Datensätze, um Maschinen für die Unterscheidung von Mustern und die Erkennung von Bildern zu trainieren. Durch die Verschmelzung von Deep Learning und Convolutional Neural Networks (CNNs) werden die Systeme großen Datensätzen ausgesetzt, damit sie selbstständig Merkmale erkennen und ihr Verständnis verfeinern können.
Im Bereich des maschinellen Lernens befähigen Algorithmen Computer dazu, den Kontext visueller Daten ohne explizite Programmierung zu verstehen. Nachvollziehbare CNNs helfen dabei, Bilder in Pixel zu zerlegen, Tags zuzuordnen und Faltungen für Vorhersagen zu nutzen. Das CNN verfeinert seine Vorhersagen iterativ, ähnlich wie die menschliche Erkennung, die sich von einfachen Formen zu komplizierten Details entwickelt.
Während CNNs sich durch das Verstehen einzelner Bilder auszeichnen, erweitern rekurrente neuronale Netze (RNNs) diese Fähigkeit auf Videoanwendungen, indem sie Computern dabei helfen, zeitliche Beziehungen zwischen Bildern zu erfassen. Die Zusammenarbeit zwischen maschinellem Lernen und CNNs ermöglicht es Maschinen, selbst zu lernen und Bilder zu erkennen, was die nuancierten Prozesse der menschlichen visuellen Wahrnehmung widerspiegelt. Im Zuge des technologischen Fortschritts wird sich die Landschaft der Computer Vision erweitern und eine Phase des intelligenten visuellen Verständnisses durch Maschinen einleiten.
Die wichtigsten Modelle der Computer Vision
Bild-Klassifizierung
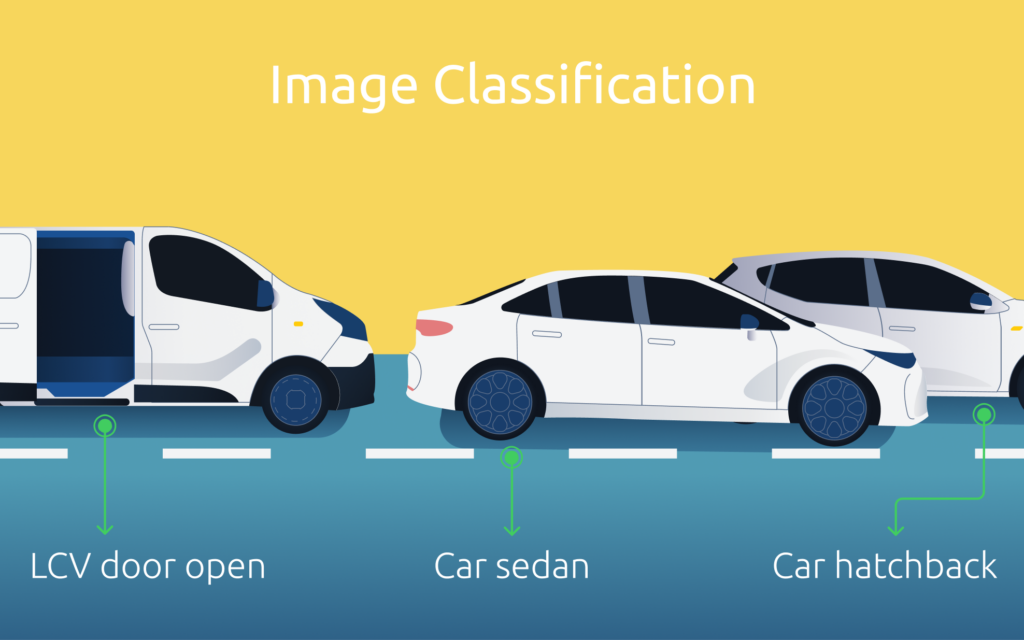
Abbildung 1: Das Bild oben zeigt, dass die Bildklassifizierung das Auto erkennen und klassifizieren kann.
Die Bildklassifizierung ist eine der grundlegenden Aufgaben in der Computer Vision, die sich auf die Mustererkennung stützt. Sie beinhaltet die Zuweisung von vordefinierten Etiketten oder Kategorien zu einem Eingabebild. CNNs haben sich als die bevorzugte Architektur für Bildklassifizierungsaufgaben herauskristallisiert. Sie nutzen die Mustererkennung durch Faltungsschichten, um automatisch hierarchische Merkmale aus Bildern zu lernen. Dadurch sind sie in der Lage, komplexe Muster und Texturen in den Daten zu erkennen. Beliebte Modelle zur Bildklassifizierung wie AlexNet, VGG und ResNet haben bei Standarddatensätzen wie ImageNet eine bemerkenswerte Genauigkeit erzielt und damit die Effektivität von Deep Learning und Mustererkennung in diesem Bereich unter Beweis gestellt.
Objekt-Erkennung
Abbildung 2: Das obige Bild ist ein Beispiel für die Objekterkennung. Es zeigt, dass das System in der Lage ist, zwei separate Autos zu identifizieren und zu kennzeichnen.
Die Objekterkennung, eine zentrale Technik der Mustererkennung in der Computer Vision, beinhaltet die Identifizierung und Lokalisierung von Objekten in Bildern oder Videos. Sie spielt insbesondere bei autonomen Fahrzeugen, aber auch bei Überwachungssystemen und Augmented Reality eine entscheidende Rolle. Bei der Objekterkennung werden entweder Algorithmen des maschinellen Lernens oder des Deep Learning eingesetzt, die die Mustererkennung nutzen, um die menschliche Intelligenz bei der Erkennung und Lokalisierung von Objekten zu imitieren.
Es gibt viele verschiedene Techniken zur Objekterkennung, aber die 3 bemerkenswertesten sind die folgenden:
- Auf Deep Learning basierende Techniken, wie R-CNN und YOLO v2, verwenden CNN, um automatisch zu lernen und Objekte in Bildern zu erkennen. Zwei wichtige Ansätze für die Objekterkennung sind die Erstellung und das Training eines benutzerdefinierten Objektdetektors von Grund auf oder die Verwendung eines vortrainierten Modells mit Transfer Learning. Zweistufige Netzwerke wie R-CNN identifizieren vor der Klassifizierung von Objekten Regionsvorschläge und erreichen so eine hohe Genauigkeit, aber eine langsamere Geschwindigkeit. Regionsvorschläge dienen als Kandidaten für Bounding Boxes, die das Netzwerk in der anschließenden Klassifizierungsphase auf potenzielle Objekte untersucht. Einstufige Netzwerke wie YOLO v2 sagen Regionen im gesamten Bild voraus. Sie bieten schnellere Ergebnisse, aber möglicherweise eine geringere Genauigkeit bei kleinen Objekten.
- Techniken des maschinellen Lernens wie ACF- und SVM-Klassifizierung unter Verwendung von HOG-Merkmalen bieten alternative Ansätze für die Objekterkennung unter Einbeziehung der Mustererkennung. Die Entscheidung zwischen Deep Learning und maschinellem Lernen hängt von Faktoren wie der Verfügbarkeit von beschrifteten Trainingsdaten und GPU-Ressourcen ab. MATLAB bietet Tools zum Erstellen und Anpassen von Objekterkennungsmodellen, die Aufgaben wie Bildbeschriftung, Algorithmenerstellung und Codegenerierung für den Einsatz auf verschiedenen Plattformen, einschließlich GPUs wie NVIDIA Jetson, erleichtern.
- Die Bildsegmentierung ist eine weitere Technik, die bei der Objekterkennung eingesetzt wird. Sie bietet einen alternativen Ansatz zur Identifizierung und Abgrenzung von Objekten in Bildern oder Videos. Bei dieser Methode wird ein Bild in Segmente unterteilt, die auf bestimmten Eigenschaften wie Farbe, Form oder Textur basieren. Die Bildsegmentierung bietet zusammen mit der Blob-Analyse und der merkmalsbasierten Erkennung zusätzliche Möglichkeiten zur Erkennung von Objekten, je nach den Anforderungen der Anwendung.
Objektverfolgung
Abbildung 3: Das obige Bild zeigt zwei sich bewegende Autos und wie die Objekterkennung sie separat identifizieren und verfolgen kann.
Bei der Objektverfolgung geht es um die kontinuierliche Überwachung der Positionen und Bewegungen von Objekten in aufeinanderfolgenden Bildern einer Videosequenz. Sie ist entscheidend für Anwendungen wie Videoüberwachung, Mensch-Computer-Interaktion und Robotik. Verfolgungsalgorithmen müssen mit Herausforderungen wie Verdeckungen, Maßstabsänderungen und unterschiedlichen Lichtverhältnissen umgehen. Algorithmen für die Verfolgung mehrerer Objekte (Multiple Object Tracking, MOT), wie der Kalman-Filter und der Partikel-Filter, werden üblicherweise für die Vorhersage und Aktualisierung von Objektpositionen im Laufe der Zeit verwendet.
Inhaltsbasierte Bildsuche
Content-Based Image Retrieval (CBIR) ermöglicht das Abrufen von Bildern aus einer Datenbank auf der Grundlage ihres visuellen Inhalts. Dazu werden die Merkmale eines abgefragten Bildes mit denen der Bilder in der Datenbank verglichen, um die ähnlichsten Bilder zu finden. Techniken zur Merkmalsextraktion, wie Farbhistogramme, Texturdeskriptoren und tiefe Merkmale, spielen in CBIR-Systemen eine entscheidende Rolle. CBIR findet Anwendung in Bildsuchmaschinen, in der medizinischen Bildanalyse und in der digitalen Bestandsverwaltung. Ein gängiges Beispiel hierfür ist eine Bildsuchmaschine wie Google Images.
Anwendungen von Computer Vision
1. Automobilindustrie
In der Automobilindustrie ist die Computer Vision von zentraler Bedeutung für die Entwicklung des autonomen Fahrens und die Verbesserung der Fahrzeugsicherheit. Integriert in fortschrittliche Fahrerassistenzsysteme (Advanced Driver-Assistance Systems, ADAS) hilft die Computer Vision bei der Erkennung von Hindernissen, dem Halten der Fahrspur und der Vermeidung von Kollisionen. Eine weitere wichtige Anwendung ist die effiziente Fahrzeuginspektion, bei der Schäden identifiziert und kategorisiert werden, um die Kosten zu senken. Bei focalx verwenden wir fortschrittliche Computer-Vision-Modelle für eine präzise und schnelle Bewertung des Fahrzeugzustands. Wenn Sie mehr darüber erfahren möchten, lesen Sie bitte unseren Artikel Car Damage Detection. Darüber hinaus können Computer Vision Systeme zur Fahrerüberwachung Anzeichen von Müdigkeit oder Ablenkung erkennen und so die Sicherheit von Fahrer und Fahrzeug erhöhen.
2. Gesundheitswesen
Die Computer Vision hat das Gesundheitswesen revolutioniert, indem sie die medizinische Bildgebung und Krankheitserkennung verbessert hat. Convolutional Neural Networks (CNNs) ermöglichen eine hochpräzise Identifizierung von Anomalien in Röntgenbildern, MRTs und CT-Scans und helfen so erheblich bei der Diagnose von Krankheiten. Während der COVID-19-Pandemie war die Computervision entscheidend für das Screening von Patienten und die Überwachung des Krankheitsverlaufs anhand von Atemmustern. Ein bemerkenswertes Beispiel ist das KI-System von Google Health für die Mammographie, das die Zahl der falsch-positiven und -negativen Ergebnisse bei Brustkrebs-Screenings erheblich reduziert und damit die Diagnosegenauigkeit verbessert hat.
3. Allgemeine Anwendungsfälle
Anwendungen der Computer Vision erstrecken sich auf alltägliche Aufgaben wie Gesichtserkennung, optische Zeichenerkennung (OCR) sowie Augmented Reality (AR) und Virtual Reality (VR). Gesichtserkennungssysteme, die auf CNNs basieren, werden in der Sicherheitsbranche, bei der Strafverfolgung und beim Entsperren von persönlichen Geräten eingesetzt. OCR-Technologie wandelt gescannte Bilder von Text in digitale Daten um und erleichtert so die Bearbeitung und Digitalisierung von Dokumenten. In der Unterhaltungsbranche und bei Spielen verbessert die Computer Vision die AR- und VR-Erlebnisse, indem sie reale Objekte erkennt und virtuelle Elemente überlagert, wodurch interaktive und immersive Umgebungen entstehen.
Fazit
Die Modelle zur Objekterkennung werden ständig verbessert, wobei neue Architekturen und Techniken die Genauigkeit und Effizienz erhöhen. Herausforderungen wie die Erkennung von Objekten in komplexen Szenen oder bei schlechten Lichtverhältnissen treiben die Forschung weiter voran. Die Kombination von Objekterkennung mit anderen Aufgaben der Computer Vision, wie z.B. Verfolgung und Segmentierung, erhöht ihre praktischen Anwendungsmöglichkeiten und macht sie zu einer vielseitigen Lösung für verschiedene Szenarien.
Computer Vision hat die Art und Weise verändert, wie Maschinen visuelle Informationen wahrnehmen und interpretieren. Aufgaben wie Bildklassifizierung, Objekterkennung, Objektverfolgung und inhaltsbasierte Bildabfrage erweitern die Fähigkeiten dieser Systeme. Dabei ist die Objekterkennung besonders wichtig für reale Anwendungen wie autonome Fahrzeuge und intelligente Überwachungssysteme. Mit dem Fortschritt der Computer Vision Technologie verspricht die Integration dieser Aufgaben, intelligentere und wahrnehmungsfähigere Maschinen zu schaffen, die zu einer neuen Ära der Mensch-Maschine-Interaktion führen.