

La Visión por Ordenador es un campo multidisciplinar que capacita a las máquinas para interpretar y comprender la información visual del mundo, reflejando las capacidades perceptivas de la visión humana. Esta tecnología transformadora ha encontrado aplicaciones no sólo en la industria automovilística, sino también en otros ámbitos, que van desde la sanidad a los sistemas de seguridad y el entretenimiento. En este artículo nos adentraremos en los entresijos técnicos de la visión por ordenador, explorando sus principios fundamentales y centrándonos en sus aplicaciones con soluciones factibles en la detección de daños en automóviles. El proceso puede dividirse en varios pasos clave:
1. Adquisición de imágenes: Captura de datos visuales a través de diversos sensores, como cámaras.
2. Preprocesamiento: Limpieza y mejora de las imágenes adquiridas para un mejor análisis.
3. Extracción de características: Identificación de patrones o características relevantes en las imágenes.
4. Toma de decisiones: Dar sentido a las características extraídas para sacar conclusiones o tomar medidas.
¿Cómo funciona la Visión Artificial?
La visión por ordenador se basa en amplios conjuntos de datos para entrenar a las máquinas en la distinción de patrones y el reconocimiento de imágenes. Mediante la fusión del aprendizaje profundo y las Redes Neuronales Convolucionales (CNN), el proceso consiste en exponer los sistemas a grandes conjuntos de datos, lo que les permite identificar características de forma autónoma y refinar su comprensión.
En el ámbito del aprendizaje automático, los algoritmos permiten a los ordenadores comprender el contexto de los datos visuales sin programación explícita. Las CNN trazables son fundamentales para descomponer las imágenes en píxeles, asignar etiquetas y utilizar convoluciones para las predicciones. La CNN refina sus predicciones de forma iterativa, de forma similar al reconocimiento humano que evoluciona desde formas básicas hasta detalles intrincados.
Mientras que las CNN destacan en la comprensión de imágenes individuales, las Redes Neuronales Recurrentes (RNN) amplían esta capacidad a las aplicaciones de vídeo, ayudando a los ordenadores a captar las relaciones temporales entre fotogramas. La colaboración entre el aprendizaje automático y las CNN permite a las máquinas autoaprender y reconocer imágenes, reflejando los matizados procesos de la percepción visual humana. A medida que avanza la tecnología, el panorama de la visión por ordenador está a punto de ampliarse, dando paso a una fase de comprensión visual inteligente por parte de las máquinas.
Modelos clave de la visión por ordenador
Clasificación de imágenes
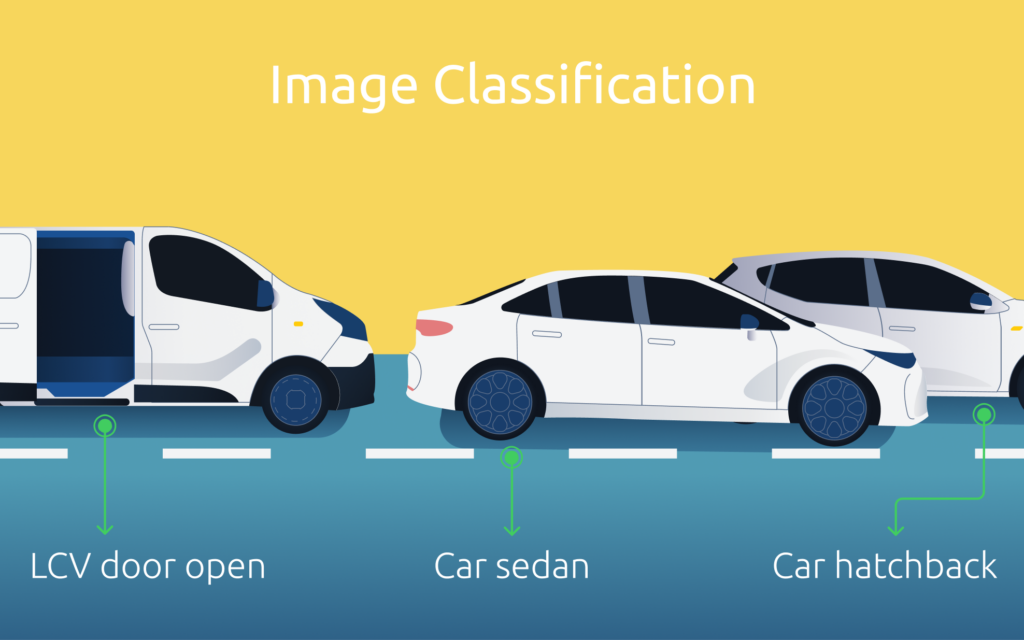
Figura 1: La imagen anterior muestra que la Clasificación de Imágenes puede detectar y clasificar el coche.
La clasificación de imágenes es una de las tareas fundacionales de la visión por ordenador, que se basa en el reconocimiento de patrones. Consiste en asignar etiquetas o categorías predefinidas a una imagen de entrada. Las CNN se han convertido en la arquitectura de referencia para las tareas de clasificación de imágenes, ya que utilizan el reconocimiento de patrones mediante capas convolucionales para aprender automáticamente características jerárquicas de las imágenes. Esto les permite discernir patrones y texturas complejos en los datos. Modelos populares de clasificación de imágenes como AlexNet, VGG y ResNet han logrado una precisión notable en conjuntos de datos estándar como ImageNet, demostrando la eficacia del aprendizaje profundo y el reconocimiento de patrones en este ámbito.
Detección de objetos
Figura 2: La imagen anterior ejemplifica la detección de objetos, demostrando su capacidad para identificar y etiquetar dos coches distintos.
La detección de objetos, una técnica fundamental de reconocimiento de patrones en visión por ordenador, consiste en identificar y localizar instancias de objetos dentro de imágenes o vídeos. Desempeña un papel especialmente crucial en vehículos autónomos, pero también en sistemas de vigilancia y realidad aumentada. La detección de objetos emplea algoritmos de aprendizaje automático o de aprendizaje profundo, aprovechando el reconocimiento de patrones para imitar la inteligencia humana en el reconocimiento y localización de objetos.
Existen muchas técnicas diferentes de detección de objetos, pero las 3 más destacadas son las siguientes:
- Las técnicas basadas en el aprendizaje profundo, como R-CNN y YOLO v2, utilizan CNN para aprender y detectar automáticamente objetos en imágenes. Dos enfoques clave para la detección de objetos consisten en crear y entrenar un detector de objetos personalizado desde cero o utilizar un modelo preentrenado con aprendizaje por transferencia. Las redes de dos etapas, como la R-CNN, identifican las propuestas de región antes de clasificar los objetos, con lo que consiguen una gran precisión pero una velocidad más lenta. Las propuestas de región sirven como cuadros delimitadores candidatos que la red examina en busca de objetos potenciales durante la fase de clasificación posterior. Las redes de una sola etapa, como YOLO v2, predicen regiones en toda la imagen, ofreciendo resultados más rápidos pero una precisión potencialmente menor para los objetos pequeños.
- Las técnicas de aprendizaje automático, como la clasificación ACF y SVM utilizando características HOG, proporcionan enfoques alternativos para la detección de objetos, incorporando el reconocimiento de patrones. La elección entre aprendizaje profundo y aprendizaje automático depende de factores como la disponibilidad de datos de entrenamiento etiquetados y recursos de GPU. MATLAB ofrece herramientas para construir y personalizar modelos de detección de objetos, facilitando tareas como el etiquetado de imágenes, la creación de algoritmos y la generación de código para su implementación en diversas plataformas, incluidas GPU como NVIDIA Jetson.
- La técnica de segmentación de imágenes es otra técnica empleada en la detección de objetos, que ofrece un enfoque alternativo para identificar y delinear objetos dentro de imágenes o vídeos. Este método consiste en dividir una imagen en segmentos basándose en propiedades específicas como el color, la forma o la textura. La segmentación de imágenes, junto con el análisis de manchas y la detección basada en características, ofrece vías adicionales para detectar objetos en función de los requisitos de la aplicación.
Seguimiento de objetos
Figura 3: La imagen anterior muestra dos coches en movimiento y cómo la detección de objetos puede identificarlos y seguirlos por separado.
El seguimiento de objetos implica la monitorización continua de las posiciones y movimientos de los objetos en fotogramas sucesivos de una secuencia de vídeo. Es crucial para aplicaciones como la videovigilancia, la interacción persona-ordenador y la robótica. Los algoritmos de seguimiento deben afrontar retos como las oclusiones, los cambios de escala y las variaciones en las condiciones de iluminación. Los algoritmos de Seguimiento de Objetos Múltiples (MOT), como el filtro de Kalman y el filtro de Partículas, se emplean habitualmente para predecir y actualizar las posiciones de los objetos a lo largo del tiempo.
Recuperación de imágenes basada en el contenido
La Recuperación de Imágenes Basada en el Contenido (CBIR) permite recuperar imágenes de una base de datos basándose en su contenido visual. Esto implica comparar las características de una imagen de consulta con las de las imágenes de la base de datos para encontrar las más similares. Las técnicas de extracción de características, como los histogramas de color, los descriptores de textura y las características profundas, desempeñan un papel crucial en los sistemas CBIR. El CBIR encuentra aplicaciones en motores de búsqueda de imágenes, análisis de imágenes médicas y gestión de activos digitales. Un ejemplo habitual es un motor de búsqueda de imágenes como Google Imágenes.
Aplicaciones de la visión por ordenador
1. Industria del automóvil
En la industria del automóvil, la visión por ordenador es fundamental para desarrollar la conducción autónoma y mejorar la seguridad de los vehículos. Integrada en los Sistemas Avanzados de Asistencia al Conductor (ADAS), la visión por ordenador ayuda a detectar obstáculos, mantener el carril y evitar colisiones. Otro uso significativo es para inspecciones eficientes de vehículos, identificando y categorizando los daños para mitigar los costes. En focalx, utilizamos modelos avanzados de visión por ordenador para realizar evaluaciones precisas y rápidas del estado del vehículo. Para saber más sobre esto, consulta nuestro artículo Detección de daños en el automóvil. Además, la visión por ordenador permite a los sistemas de control del conductor detectar signos de fatiga o distracción, aumentando así la seguridad del conductor y del vehículo.
2. Industria sanitaria
La visión por ordenador ha revolucionado la industria sanitaria al mejorar las imágenes médicas y la detección de enfermedades. Las redes neuronales convolucionales (CNN) permiten identificar con gran precisión las anomalías en radiografías, resonancias magnéticas y tomografías computarizadas, lo que ayuda significativamente al diagnóstico de enfermedades. Durante la pandemia de COVID-19, la visión por ordenador fue crucial para examinar a los pacientes y controlar la progresión de la enfermedad a través de los patrones respiratorios. Un ejemplo notable es el sistema de IA de Google Health para mamografías, que ha reducido sustancialmente los falsos positivos y negativos en las pruebas de detección del cáncer de mama, mejorando así la precisión del diagnóstico.
3. Casos de uso general
Las aplicaciones de la visión por ordenador se extienden a tareas cotidianas como el reconocimiento facial, el reconocimiento óptico de caracteres (OCR) y la realidad aumentada (RA) y virtual (RV). Los sistemas de reconocimiento facial, impulsados por CNN, se utilizan en seguridad, aplicación de la ley y desbloqueo de dispositivos personales. La tecnología OCR convierte imágenes escaneadas de texto en datos digitales, facilitando la manipulación y digitalización de documentos. En entretenimiento y juegos, la visión por ordenador mejora las experiencias de RA y RV detectando objetos del mundo real y superponiéndolos a elementos virtuales, creando entornos interactivos e inmersivos.
Conclusión
Los modelos de detección de objetos mejoran continuamente, con nuevas arquitecturas y técnicas que aumentan la precisión y la eficacia. Retos como la detección de objetos en escenas complejas o en condiciones de poca luz impulsan la investigación en curso. La combinación de la detección de objetos con otras tareas de visión por ordenador, como el seguimiento y la segmentación, aumenta sus aplicaciones prácticas, convirtiéndola en una solución versátil para diversos escenarios.
La visión por ordenador ha transformado la forma en que las máquinas perciben e interpretan la información visual. Tareas como la clasificación de imágenes, la detección de objetos, el seguimiento de objetos y la recuperación de imágenes basada en el contenido mejoran las capacidades de estos sistemas. Entre ellas, la detección de objetos es especialmente crucial para las aplicaciones del mundo real, incluidos los vehículos autónomos y los sistemas de vigilancia inteligentes. A medida que avanza la tecnología de visión por ordenador, la integración de estas tareas promete crear máquinas más inteligentes y perceptivas, lo que conducirá a una nueva era de interacción hombre-máquina.