Computer Vision is a multidisciplinary field that empowers machines to interpret and understand visual information from the world, mirroring the perceptual capabilities of human vision. This transformative technology has found applications not only in the automotive industry but also in various other domains, ranging from healthcare to security systems and entertainment. In this article, we will delve into the technical intricacies of computer vision, exploring its fundamental principles and focusing on its applications with tractable solutions in damage detection for cars.

At its core, computer vision involves the development of algorithms and models that enable machines to gain insights from visual data. The process can be broken down into several key steps:
1. Image acquisition: Capturing visual data through various sensors such as cameras.
2. Preprocessing: Cleaning and enhancing the acquired images for better analysis.
3. Feature extraction: Identifying relevant patterns or characteristics in the images.
4. Decision-making: Making sense of the extracted features to draw conclusions or take actions.
How does Computer Vision work?
Computer vision relies on extensive datasets to train machines in distinguishing patterns and recognizing images. Through the fusion of deep learning and Convolutional Neural Networks (CNNs), the process involves exposing systems to large datasets, allowing them to autonomously identify features and refine their comprehension.
In the realm of machine learning, algorithms empower computers to understand the context of visual data without explicit programming. Tractable CNNs are instrumental, in breaking down images into pixels, assigning tags, and utilizing convolutions for predictions. The CNN refines its predictions iteratively, akin to human recognition evolving from basic shapes to intricate details.
While CNNs excel in understanding individual images, Recurrent Neural Networks (RNNs) extend this capability to video applications, aiding computers in grasping temporal relationships between frames. The collaboration between machine learning and CNNs enables machines to self-learn and recognize images, mirroring the nuanced processes of human visual perception. As technology advances, the landscape of computer vision is poised to expand, ushering in a phase of intelligent visual comprehension by machines.
Computer Vision’s Key models
Image Classification
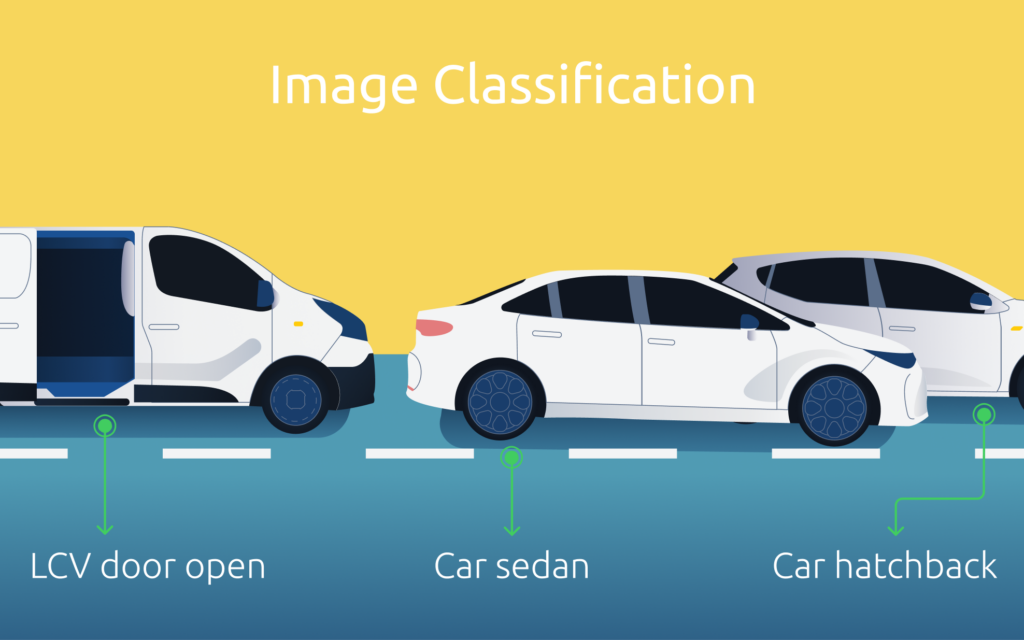
Figure 1: The image above showcases that Image Classification can detect and classify the car.
Image classification is one of the foundational tasks in computer vision, relying on pattern recognition. It involves assigning predefined labels or categories to an input image. CNNs have emerged as the go-to architecture for image classification tasks, utilizing pattern recognition through convolutional layers to automatically learn hierarchical features from images. This enables them to discern complex patterns and textures within the data. Popular image classification models like AlexNet, VGG, and ResNet have achieved remarkable accuracy on standard datasets like ImageNet, showcasing the effectiveness of deep learning and pattern recognition in this domain.
Object Detection
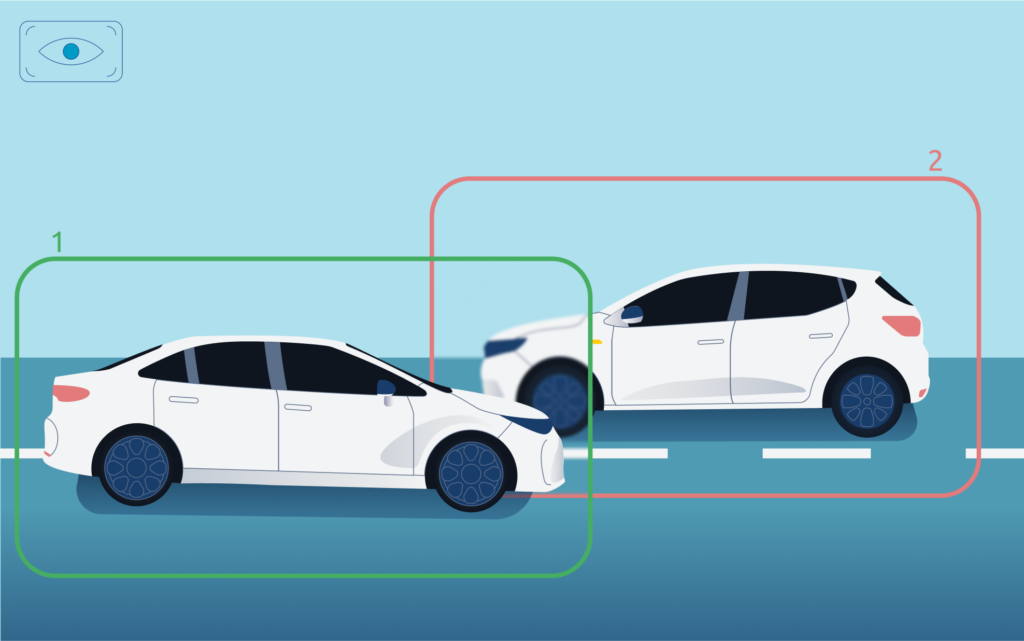
Figure 2: The image above exemplifies object detection, demonstrating its capability to identify and label two separate cars.
Object detection, a pivotal pattern recognition technique in computer vision, involves identifying and locating instances of objects within images or videos. It plays an especially crucial role in autonomous vehicles but as surveillance systems and augmented reality. Object detection employs either machine learning or deep learning algorithms, leveraging pattern recognition to mimic human intelligence in recognizing and localizing objects.
There are many different object detection techniques, but the 3 most notable ones are the following:
• Deep learning-based techniques, such as R-CNN and YOLO v2, use CNN to automatically learn and detect objects in images. Two key approaches for object detection involve creating and training a custom object detector from scratch or using a pre-trained model with transfer learning. Two-stage networks like R-CNN identify region proposals before classifying objects, achieving high accuracy but slower speeds. Region proposals serve as candidate bounding boxes that the network examines for potential objects during the subsequent classification phase. Single-stage networks like YOLO v2 predict regions across the entire image, offering faster results but potentially lower accuracy for small objects.
• Machine learning techniques, such as ACF and SVM classification using HOG features, provide alternative approaches for object detection, incorporating pattern recognition. The choice between deep learning and machine learning depends on factors like the availability of labeled training data and GPU resources. MATLAB offers tools for building and customizing object detection models, facilitating tasks like image labeling, algorithm creation, and code generation for deployment on various platforms, including GPUs like NVIDIA Jetson.
• Image segmentation technique is another technique employed in object detection, offering an alternative approach to identify and delineate objects within images or videos. This method involves dividing an image into segments based on specific properties such as color, shape, or texture. Image segmentation, along with blob analysis and feature-based detection, provides additional avenues for detecting objects depending on the application’s requirements.
Object Tracking

Figure 3: The image above showcases two moving cars and how object detection can identify and track them separately.
Object tracking involves the continuous monitoring of objects’ positions and movements in successive frames of a video sequence. It is crucial for applications like video surveillance, human-computer interaction, and robotics. Tracking algorithms must handle challenges such as occlusions, changes in scale, and variations in lighting conditions. Multiple Object Tracking (MOT) algorithms, such as the Kalman filter and Particle filter, are commonly employed for predicting and updating object positions over time.
Content-Based Image Retrieval
Content-Based Image Retrieval (CBIR) enables the retrieval of images from a database based on their visual content. This involves comparing the features of a query image with those of images in the database to find the most similar ones. Feature extraction techniques, such as color histograms, texture descriptors, and deep features, play a crucial role in CBIR systems. CBIR finds applications in image search engines, medical image analysis, and digital asset management. A common example of this an image search engine such as Google Images.
Applications of Computer Vision
1. Automotive Industry
In the automotive industry, computer vision is pivotal for developing autonomous driving and enhancing vehicle safety. Integrated within Advanced Driver-Assistance Systems (ADAS), computer vision aids in obstacle detection, lane keeping, and collision avoidance. Another significant use is for efficient vehicle inspections, identifying and categorizing damages to mitigate costs. At focalx, we utilize advanced computer vision models for precise and quick assessments of vehicle condition. To learn more about this, please refer to our article, Car Damage Detection. Furthermore, computer vision enables driver monitoring systems to detect signs of fatigue or distraction, thereby increasing driver and vehicle safety.
2. Healthcare Industry
Computer vision has revolutionized the healthcare industry by enhancing medical imaging and disease detection. Convolutional Neural Networks (CNNs) enable high-accuracy identification of anomalies in X-rays, MRIs, and CT scans, significantly aiding in disease diagnosis. During the COVID-19 pandemic, computer vision was crucial in screening patients and monitoring disease progression through respiration patterns. A notable example is Google Health’s AI system for mammography, which has substantially reduced false positives and negatives in breast cancer screenings, thereby improving diagnostic accuracy.
3. General Use Cases
Computer vision applications extend to everyday tasks such as facial recognition, optical character recognition (OCR), and augmented reality (AR) and virtual reality (VR). Facial recognition systems, powered by CNNs, are used in security, law enforcement, and personal device unlocking. OCR technology converts scanned images of text into digital data, facilitating easy manipulation and digitization of documents. In entertainment and gaming, computer vision enhances AR and VR experiences by detecting real-world objects and overlaying virtual elements, creating interactive and immersive environments.
Conclusion
Object detection models are continually improving, with new architectures and techniques enhancing accuracy and efficiency. Challenges like detecting objects in complex scenes or low-light conditions drive ongoing research. Combining object detection with other computer vision tasks, such as tracking and segmentation, increases its practical applications, making it a versatile solution for various scenarios.
Computer vision has transformed how machines perceive and interpret visual information. Tasks like image classification, object detection, object tracking, and content-based image retrieval enhance the capabilities of these systems. Among these, object detection is particularly crucial for real-world applications, including autonomous vehicles and smart surveillance systems. As computer vision technology progresses, integrating these tasks promises to create smarter and more perceptive machines, leading to a new era of human-machine interaction.